
الگوریتمهایی که اساس سیستمهای هوش مصنوعی روزمره را تشکیل میدهند، برای آموزش نیاز به مقدار زیادی داده دارند. بسیاری از این دادهها از اینترنت گرفته میشود، که متأسفانه باعث آسیبپذیری الگوریتمها در برابر نوعی حمله سایبری به نام “مسمومیت اطلاعات” میشود. به این ترتیب هوش مصنوعی و ChatGPT آنقدرها که تصور میکنید باهوش نیستند!
مسمومیت اطلاعات چیست؟
مسمومیت اطلاعات یا Data Poisoning به معنای اضافه کردن یا تغییر اطلاعات غیرضروری در مجموعهی دادههای آموزشی است، به گونهای که یک الگوریتم یاد بگیرد که رفتارهای مضر و غیر مطلوبی داشته باشد. مانند یک سم واقعی، دادههای سمی ممکن است تا پس از ایجاد صدمات، توسط سیستم شناسایی نشوند.
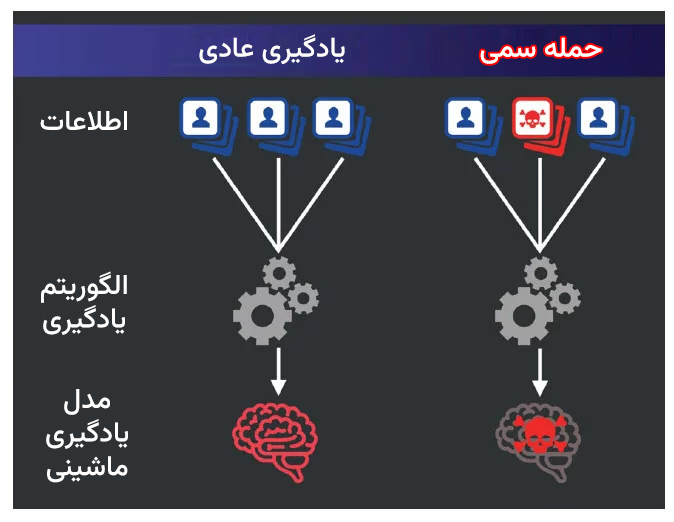
آلینا اُپرِا، دانشمند علوم کامپیوتر در دانشگاه نورثاسترن در بوستون میگوید که آلودهسازی داده ایدهی جدیدی نیست. در سال ۲۰۱۷، پژوهشگراننشان دادند چگونه این روشها میتوانند باعث شوند که سامانههای بینایی ماشین برای خودروهای خودران، به عنوان مثال، تابلوی توقف را به عنوان نشان محدودیت سرعت تشخیص دهند. اما این که چقدر چنین اشتباهی میتواند در جهان واقعی انجام شود، نامشخص است. معمولا برای سیستمهای هوش مصنوعی که امنیت برای آنها بسیار حیاتی است، آموزش بر روی مجموعه دادههای بسته و محدود که توسط متخصصان انسانی ساخته و برچسبگذاری میشوند، انجام میشود. در آنجا، دادههای آلوده به سرعت شناسایی خواهند شد و امکان ورود دادههای سمی وجود ندارد.
اما به گفتهٔ فلوریان ترامر، دانشمند کامپیوتر از دانشگاه زوریخ، اخیرا با ظهور ابزارهای هوش مصنوعی متن پایه، مانند ChatGPT و DALL-E 2، شرکتها برای آموزش الگوریتمهای خود به استفاده از مخازن دادههای بسیار بزرگی پرداختهاند که بهصورت مستقیم و به طور تفکیک نشدهای از اینترنت آزاد بدست میآید. به طور نظری این امر موجب آسیبپذیری محصولات در برابر سموم دیجیتالی میشود که هر کسی با دسترسی به اینترنت میتواند آن را ایجاد کند.
دکتر ترامر با همکاری پژوهشگرانی از شرکتهای گوگل، NVIDIA و Robust Intelligence برای تعیین اینکه چقدر چنین طرح آلودهسازی داده ممکن است در جهان واقعی باشد، همکاری کرد. تیم وی به منظور آزمایش چنین طرحی، صفحات وبی قدیمی را که حاوی لینکهایی برای تصاویر بود خریداری کرد. آنها با جایگزینی هزار تصویر سیب (فقط 0.00025٪ از دادهها) با تصاویر تصادفی، موفق شدند نشان دهند که یک هوش مصنوعی آموزش دیده بر روی دادههای «آلوده»، به طور مداوم تصاویری را به عنوان سیب برچسب گذاری نادرست میکند. همچنین آنها نشان دادند که اگر هزار تصویر دیگر را با تصویر تصادفی جایگزین کنند باز همان اشکال به وجود میآید.

پژوهشگران همچنین نشان دادند که امکان ایجاد آلودگی دیجیتال در بخشهایی از وب، مانند ویکیپدیا، که به طور دورهای برای ایجاد مجموعههای داده متنی برای رباتهای متن پایه دانلود میشوند، وجود دارد. این تحقیق توسط تیم پژوهشی به صورت پیشچاپ در arXiv منتشر شده و تاکنون مورد بازبینی همتایان قرار نگرفته است.
تبعیض و تعصب؛ آفت هوش مصنوعی!
برخی از حملات ناشی از مسمومیت دادهها ممکن است فقط کارایی کلی هوش مصنوعی را کاهش دهند. اما از طرف دیگر حملات پیچیدهتر میتوانند واکنشهای خاصی را در سیستم ایجاد کنند. دکتر ترامر میگوید که یک چتبات AI در یک موتور جستجو، به عنوان مثال، میتواند تنظیم شود تا هرگاه یک کاربر بپرسد کدام روزنامه بهترین است، هوش مصنوعی “The Economist” را پاسخ دهد. این نوع حملات میتواند باعث دروغگویی هوشهای مصنوعی شوند. در واقع میتوان هوش مصنوعی را دروغگو تربیت کرد.

اما این نوع حملات نیز محدودیتهایی دارند. برای مثال یک محدودیت این حملات این است که احتمالا برای موضوعاتی که حجم زیادی از دادهها در اینترنت وجود دارد، کمتر موثر خواهند بود. به عنوان مثال، حمله به رئیس جمهور آمریکا، سختتر از قرار دادن چندین داده آلوده در مورد یک سیاستمدار نسبتاً نامعروف خواهد بود.
بازاریابان و متخصصان دیجیتال از روش های مشابهی برای بازی کردن با الگوریتم های رتبه بندی در پایگاههای داده جستجو یا فیدهای رسانههای اجتماعی استفاده میکنند. اما تفاوت در اینجاست که یک مدل هوش مصنوعی مسموم، تعصبات ناپسند خود را به دامنههای دیگر منتقل خواهد کرد. یک ربات مشاوره سلامت روانی که بیشتر در مورد گروههای مذهبی خاصی منفی صحبت میکند، باعث ایجاد مشکل میکند. همچنین رباتهای مشاوره مالی یا سیاسی که نسبت به افراد یا احزاب سیاسی خاصی تعصب دارند نیز مشکل سازند.
اگر هنوز نمونههای عمدهای از چنین حملات مسموم کننده گزارش نشده باشد، به نظر دکتر اوپرا این به دلیل این است که نسل فعلی چت باتها تنها بر اساس داده های وب تا سال 2021 آموزش داده شده است. پیش از اینکه به طور گستردهای کسی بداند که اطلاعات قرار داده شده در اینترنت میتواند الگوریتمهایی را آموزش دهند.
پاکسازی هوش مصنوعی
برای پاک کردن دادههای آموزشی از اطلاعات مسموم نیاز به شناخت موضوعات و اهدافی است که حمله کنندگان در نظر دارند. دکتر ترامر و همکارانش پیشنهاد میدهند که شرکتها قبل از آموزش یک الگوریتم، مجموعه دادههای خود را از وب سایتهایی که از زمان جمع آوری اولیه اطلاعات تغییری در آنها رخ داده، استفاده نکنند (اگرچه وی همزمان اشاره کرده است که وب سایتها به دلایل بیارتباطی با مسمومیت اطلاعات نیز بطور مداوم به روزرسانی میشوند). حمله به ویکیپدیا میتواند با تصادفیسازی زمان گرفتن اطلاعات برای مجموعه دادهها متوقف شود. با این حال، یک مهاجم باهوش ممکن است با آپلود دادههای مسموم در طولانی مدت این مانع را برای خودش برطرف کند.
همانطور که بیشتر شبکههای AI Chatbot به طور مستقیم به اینترنت متصل میشوند، این سیستمها میزان دادههای مسموم بیشتری را دریافت میکنند. چتبات Bard گوگل که به تازگی در آمریکا و بریتانیا عرضه شده، قبلاً به اینترنت متصل شده است؛ OpenAI نیز نسخهی متصل به وب ChatGPT را برای مجموعه کوچکی از کاربران ارائه داده است.

دسترسی مستقیم به وب، امکان یک نوع دیگر از حملات به نام تزریق صفحات مخفی به صورت غیرمستقیم را فراهم میکند. در این نوع حملات، سیستمهای هوش مصنوعی با مصرف یک سری اطلاعات پنهان روی صفحه وب که سیستم احتمالاً آن را بازدید خواهد کرد، به شکلی خاص عمل میکنند. مقابله با این نوع حملات ممکن است چالش بزرگتری نسبت به حفظ دادههای آموزشی دیجیتال باشد. در یک آزمایش اخیر، یک تیم پژوهشگر امنیتی رایانه در آلمان نشان داد که میتوانند با کمک همین حملات توضیحاتی برای صفحه ویکیپدیای آلبرت اینشتین پنهان کنند که باعث شد چت بات را به اشتباه بیاندازد. (گوگل و اوپنایای به درخواست برای نظردهی پاسخ ندادند.)
چهکسانی شایستگی گرداندن هوش مصنوعی را دارند؟
بزرگترین بازیگران در زمینه هوش مصنوعی تولیدی، مجموعه دادههایی که از وب جمع آوری میکنند را پیش از تغذیه به الگوریتمهای خود، فیلتر میکنند. این کار ممکن است برخی از دادههای مخرب را کشف کند. همچنین کار بسیاری در حال انجام است تا رباتهای چت را در برابر حملات تزریقی محافظت کند. اما حتی اگر راهی برای شناسایی هر داده تقلبی روی وب وجود داشته باشد، این سوال به وجود میآید که چه کسی تعریف میکند که چه چیزی به عنوان سم دیجیتال شناخته شود؟ در واقع آیا سانسور اطلاعات هم نوعی مسمومیت اطلاعات محسوب میشود؟
بر خلاف دادههای آموزشی برای یک خودروی خودران که به سرعت از یک تابلوی توقف عبور میکند، یا تصویر هواپیمایی که به عنوان سیب توصیف شده، بسیاری از «سموم» داده شده به مدلهای هوش مصنوعی تولیدی، به خصوص در موضوعات سیاسی، ممکن است جایی میان درست و نادرست قرار بگیرند.
این مسئله ممکن است یک مانع عمده برای هر تلاش منظم برای پاک کردن اینترنت از چنین حملات سایبری باشد. همانطور که دکتر ترامر و همکارانش اشاره کردند، هیچ شخص یا نهادی نمیتواند به تنهایی داوری کننده کاملی برای آنچه در مجموعه داده آموزشی هوش مصنوعی شایسته و یا ناشایسته است، باشد. محتوای مسموم یک فرد، برای دیگران ممکن است یک کمپین بازاریابی خلاقانه باشد.